
UniversalRAG انقلابی در پاسخگویی هوش مصنوعی با جستجوی چندوجهی و هوشمند
کلید طلایی برای غلبه بر محدودیتهای مدلهای زبانی بزرگ
مقدمه
مدلهای بزرگ زبانی (LLMs) مانند ChatGPT، انقلابی در تعامل ما با ماشینها ایجاد کردهاند. توانایی آنها در درک و تولید متن شبهانسانی، کاربردهای بیشماری از دستیاران مجازی گرفته تا تولید محتوا را ممکن ساخته است. با این حال، این مدلها بدون نقص نیستند. یکی از چالشهای بزرگ آنها، «توهم» یا ارائه اطلاعات نادرست، بهویژه در مورد موضوعات جدید یا بسیار تخصصی است. همچنین، دانش آنها محدود به دادههایی است که با آن آموزش دیدهاند.
برای غلبه بر این محدودیت، تکنیکی به نام تولید مبتنی بر بازیابی (Retrieval-Augmented Generation - RAG) ظهور کرد. ایده اصلی RAG ساده اما قدرتمند است: قبل از اینکه LLM به یک سوال پاسخ دهد، ابتدا اطلاعات مرتبط از یک منبع دانش خارجی (مانند ویکیپدیا یا پایگاه دادههای داخلی یک شرکت) بازیابی میشود و سپس این اطلاعات به همراه سوال اصلی به LLM داده میشود تا پاسخی دقیقتر و مبتنی بر واقعیت تولید کند.
اما نسل فعلی سیستمهای RAG نیز با محدودیتهایی مواجه است. این مقاله از پژوهشگران برجسته KAIST و DeepAuto.ai به معرفی یک چارچوب نوآورانه به نام UniversalRAG میپردازد که قصد دارد این محدودیتها را برطرف کرده و افقهای جدیدی را در زمینه RAG بگشاید.
چالشهای نسل فعلی RAG: چرا به UniversalRAG نیاز داریم؟
سیستمهای RAG موجود، با وجود کاراییشان، اغلب در چند حوزه کلیدی دچار ضعف هستند:
- محدودیت به متن: اکثر سیستمهای RAG اولیه، عمدتاً بر روی منابع متنی تمرکز داشتهاند. در حالی که دنیای اطلاعات سرشار از دادههای بصری مانند تصاویر و ویدیوهاست که میتوانند برای پاسخ به بسیاری از سوالات، حیاتی باشند.
- عملکرد بر روی یک نوع محتوای خاص: حتی تلاشهای اخیر برای گسترش RAG به سایر رسانهها (مانند تصاویر یا ویدیوها)، معمولاً بر روی یک نوع محتوای خاص و یک پایگاه داده منفرد متمرکز بودهاند. (به عنوان مثال، در تصویر ۱ بخش B ، یک RAG ویدیویی برای سوال «چگونه میتوانم چرخ دوچرخه را تعویض کنم؟» نمایش داده شده که فقط از پیکره ویدیویی استفاده میکند.
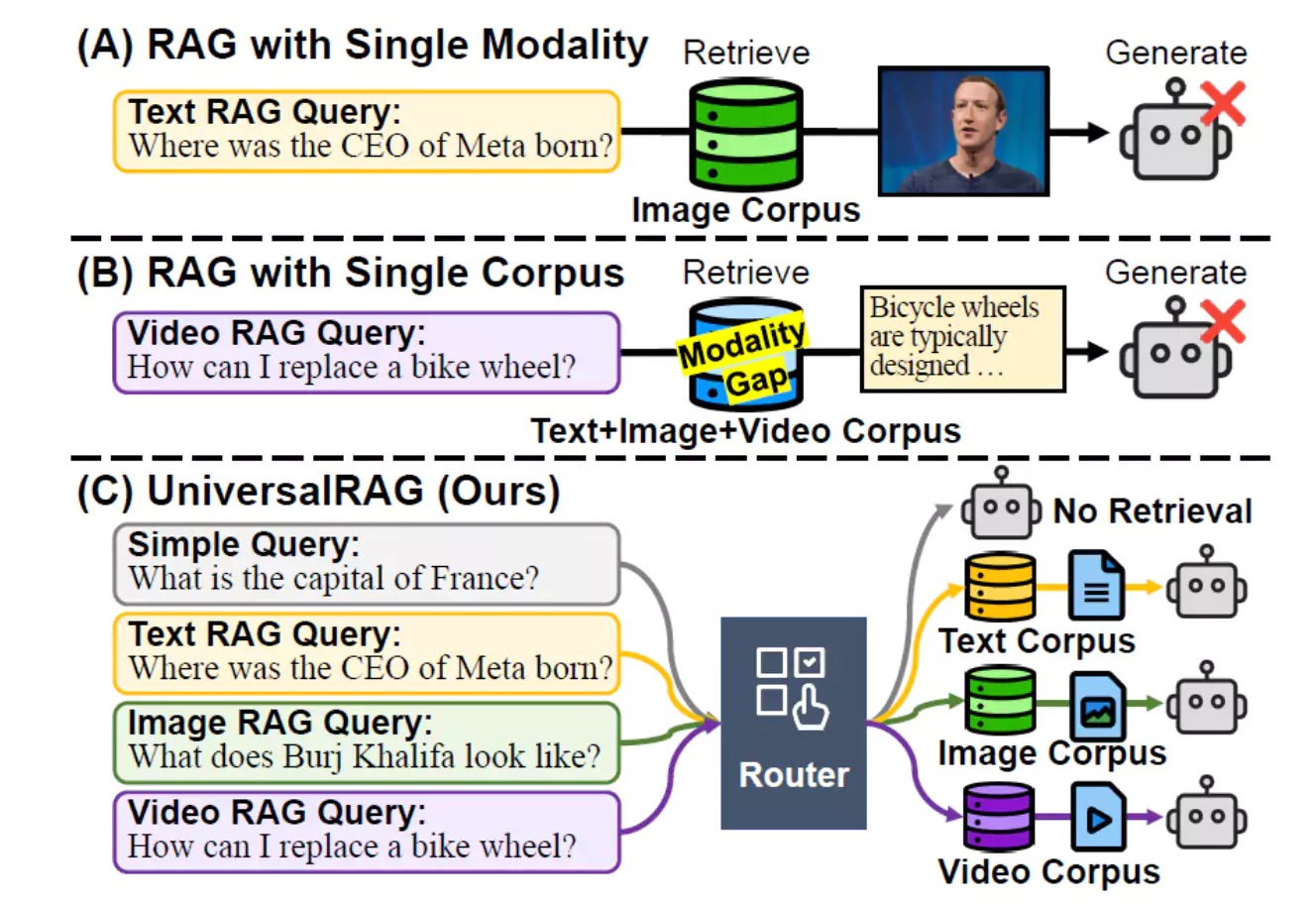
تصویر۱: (a و b) محدودیتهای روشهای موجود RAG و (c) چارچوب پیشنهادی UniversalRAG.
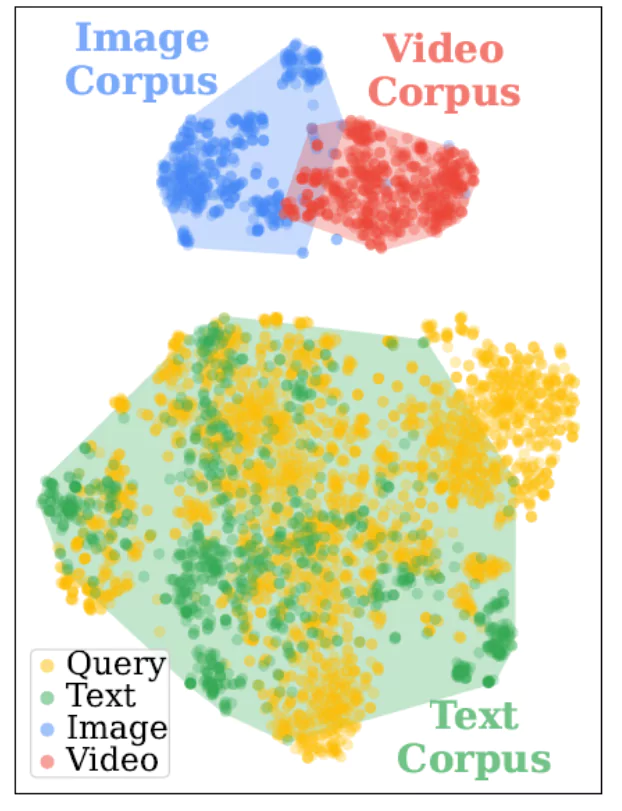
تصویر۲: تجسم t-SNE از فضای جاسازی یکپارچه
- تنوع نیازهای کاربران: کاربران در دنیای واقعی، سوالاتی با نیازهای دانشی بسیار متنوع مطرح میکنند. برخی سوالات با متن پاسخ داده میشوند (مثلاً «پایتخت فرانسه کجاست؟»)، برخی نیاز به درک بصری از تصاویر دارند (مثلاً «برج خلیفه چه شکلی است؟») و برخی دیگر به استدلال زمانی بر اساس ویدیوها نیاز دارند (مثلاً «مراحل تعویض روغن ماشین چیست؟»). یک سیستم RAG که فقط به یک نوع منبع دانش دسترسی دارد، نمیتواند به این طیف وسیع از نیازها پاسخ دهد.
- شکاف رسانهای: (Modality Gap) یک رویکرد ساده برای پشتیبانی از چندین نوع رسانه، ترکیب تمام دادهها (متن، تصویر، ویدیو) در یک پایگاه داده یکپارچه و استفاده از یک انکودر چندوجهی برای ایجاد یک فضای بازنمایی مشترک است. با این حال، پژوهشگران دریافتهاند که این روش از «شکاف رسانهای» رنج میبرد. به این معنی که سیستم تمایل دارد دادههایی را بازیابی کند که از نظر نوع رسانه با سوال مطابقت دارند، حتی اگر اطلاعات مرتبط در رسانه دیگری موجود باشد. به عنوان مثال، اگر سوال متنی باشد، سیستم ممکن است حتی برای سوالی که به تصویر نیاز دارد، متن بازیابی کند. تصویر ۲ این پدیده را به خوبی با نمایش خوشهبندی دادهها بر اساس نوع رسانه به جای معنای آنها، نشان میدهد.
معرفیUniversalRAG : راهکاری جامع و هوشمند
با هدف غلبه بر این چالشها، چارچوب UniversalRAG طراحی شده است. این چارچوب نوین، دانش توزیعشده در پیکرههای اطلاعاتی مختلف با انواع رسانهها (متن، تصویر، ویدیو) و سطوح مختلف جزئیات (دانهبندی) را گرد هم میآورد. نوآوریهای کلیدی UniversalRAG عبارتند از:
- مسیریابی آگاه از نوع محتوا (Modality-Aware Routing): به جای تلاش برای گنجاندن همه چیز در یک فضای یکپارچه، UniversalRAG رویکرد متفاوتی اتخاذ میکند. این سیستم برای هر نوع محتوا (متن، تصویر، ویدیو) پیکرههای اطلاعاتی (Corpora) و فضاهای برداری جداگانهای را حفظ میکند. سپس، یک ماژول هوشمند به نام «مسیریاب» (Router) وارد عمل میشود. وظیفه مسیریاب این است که بر اساس سوال ورودی کاربر، به صورت پویا تشخیص دهد که کدام نوع محتوا (و در نتیجه کدام پیکره اطلاعاتی) برای پاسخگویی به آن سوال مناسبتر است. سپس، فرآیند بازیابی اطلاعات به طور هدفمند فقط از آن پیکره خاص انجام میشود. این استراتژی نه تنها مشکل «شکاف رسانهای» را دور میزند، بلکه امکان افزودن آسان انواع محتوای جدید در آینده را نیز فراهم میکند. (نمای کلی این فرآیند در تصویر ۱ بخش c قابل مشاهده است).
- بازیابی آگاه از سطح جزئیات (Granularity-Aware Retrieval): فراتر از نوع محتوا، سطح جزئیات یا «دانهبندی» (Granularity) دادهها نیز نقش حیاتی در کیفیت بازیابی و تولید پاسخ دارد. سوالات مختلف، حتی در یک نوع محتوای یکسان، به سطوح متفاوتی از جزئیات نیاز دارند. به عنوان مثال: یک سوال تحلیلی پیچیده ممکن است به یک سند متنی طولانی یا یک ویدیوی کامل برای درک زمینه نیاز داشته باشد. یک سوال ساده برای یافتن یک حقیقت خاص، ممکن است با یک پاراگراف کوتاه یا یک کلیپ ویدیویی چند ثانیهای به بهترین شکل پاسخ داده شود. برای پاسخ به این نیاز، UniversalRAG هر نوع محتوا را به چندین سطح دانهبندی تقسیم میکند و آنها را در پیکرههای مجزا سازماندهی میکند:
متن: علاوه بر اسناد کامل (Document-level)، به پاراگرافهای مجزا (Paragraph-level) نیز تقسیم میشود.
ویدیو: علاوه بر ویدیوهای کامل (Full-length videos)، به کلیپهای کوتاه (Short clips) نیز تقسیم میشود.
تصاویر: ذاتاً دانهبندی ریزی دارند و به همان صورت حفظ میشوند. مسیریاب در UniversalRAG نه تنها نوع محتوا، بلکه سطح دانهبندی مناسب را نیز برای هر سوال تشخیص میدهد. علاوه بر این، یک گزینه «بدون بازیابی» (No Retrieval) نیز برای سوالات سادهای که LLM میتواند مستقیماً و بدون نیاز به دانش خارجی به آنها پاسخ دهد، در نظر گرفته شده است. این امر به افزایش کارایی سیستم کمک میکند.
هوش مسیریاب: مغز متفکر UniversalRAG
مسیریاب، جزء حیاتی UniversalRAG است که تصمیم میگیرد کدام منبع اطلاعاتی برای هر سوال مناسبتر است. پژوهشگران دو رویکرد را برای طراحی این مسیریاب بررسی کردهاند:
- مسیریاب بدون نیاز به آموزش (Training-free Router): این رویکرد از دانش و تواناییهای استدلالی ذاتی مدلهای بزرگ زبانی از پیش آموزشدیده (مانند GPT-4o) بهره میبرد. با ارائه یک دستورالعمل دقیق (Prompt) که وظیفه مسیریابی را توصیف میکند، با ارائه یک دستورالعمل دقیق (Prompt) که وظیفه مسیریابی را توصیف میکند، به همراه چند مثال درونمتنی (in-context examples)، LLM میتواند نوع بازیابی مناسب (مثلاً «پاراگراف»، «سند»، «تصویر»، «کلیپ»، «ویدیو» یا «بدون بازیابی») را برای سوال دادهشده پیشبینی کند. نمونهای از این دستورالعمل در تصویر ۳ ارائه شده است.

تصویر۳: پرامپتی برای مسیردهی درخواست بدون نیاز به آموزش
- مسیریاب آموزشدیده (Trained Router): در این رویکرد، یک مدل مسیریاب مجزا برای تصمیمگیری دقیقتر آموزش داده میشود. چالش اصلی در اینجا، نبود دادههای برچسبدار (query-label pairs) برای انتخاب بهینه پیکره است. برای حل این مشکل، پژوهشگران با بهرهگیری از ویژگیهای خاص مجموعه دادههای محکزنی (benchmarks) موجود، یک مجموعه داده آموزشی برای مسیریاب ایجاد کردهاند. به عنوان مثال، سوالات از مجموعه دادههایی که برای پاسخگویی تنها به دانش پارامتریک مدل نیاز دارند، با برچسب «بدون بازیابی» مشخص شدهاند. سوالات از مجموعه دادههای RAG تکمرحلهای با برچسب «پاراگراف» و سوالات از مجموعه دادههای RAG چندمرحلهای با برچسب «سند» مشخص شدهاند. به طور مشابه، برای سوالات تصویری و ویدیویی نیز برچسبهای «تصویر»، «کلیپ» یا «ویدیو» بر اساس ماهیت سوالات در آن مجموعه دادهها اختصاص داده شده است.
نتایج و عملکرد UniversalRAG در عمل
عملکرد UniversalRAG بر روی 8 مجموعه داده محکزنی مختلف که انواع رسانهها و سطوح دانهبندی را پوشش میدهند، به طور گسترده ارزیابی شده است. نتایج کلیدی عبارتند از:
- برتری جامع: UniversalRAG به طور مداوم از تمام روشهای پایه (که یا فقط بر یک نوع محتوا تمرکز دارند یا از یک فضای برداری یکپارچه استفاده میکنند) در امتیاز میانگین عملکرد بهتری نشان داده است. این موضوع در شکل ۴ که میانگین امتیازها را برای مدلهای مختلف نمایش میدهد، به وضوح قابل مشاهده است.
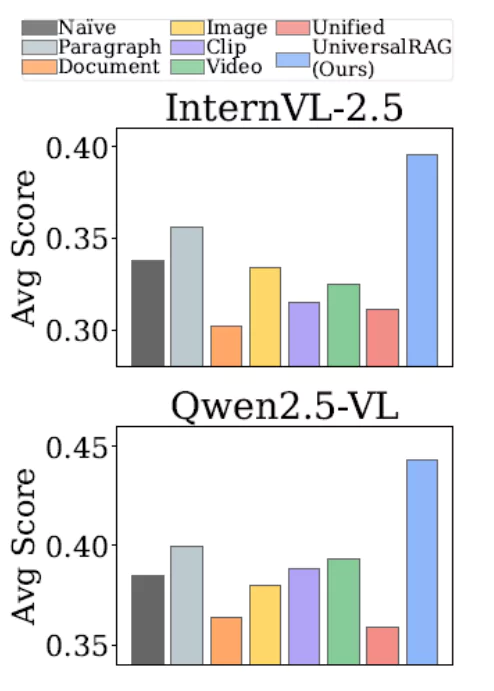
تصویر۴: میانگین نمرات پایه و UniversalRAG
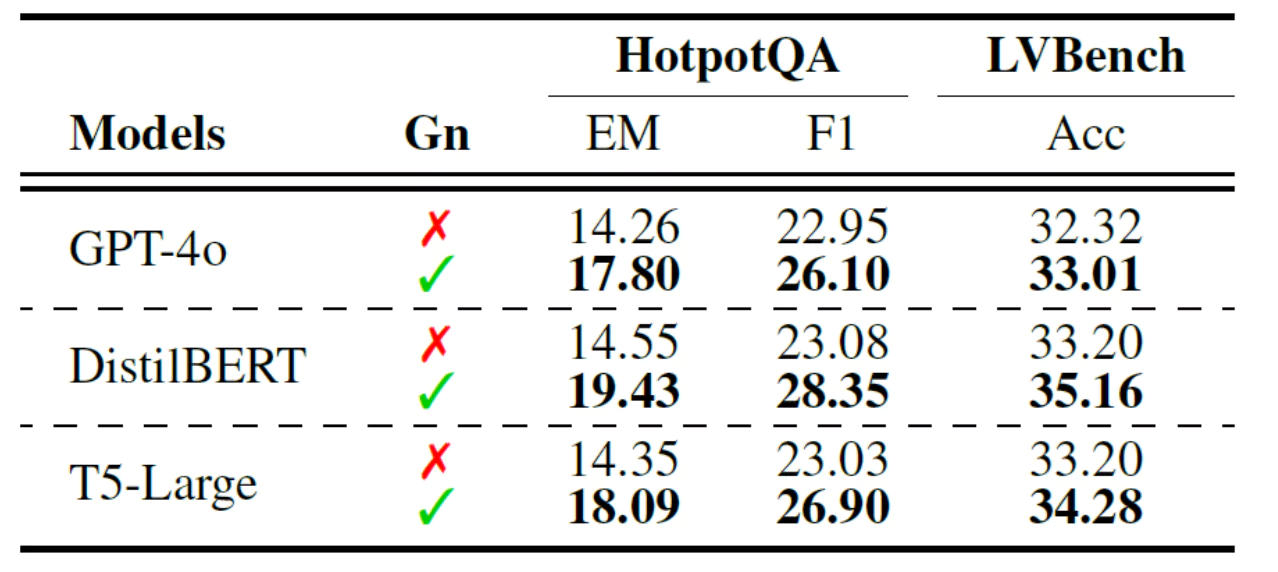
تصویر۵: تأثیر میزان جزئینگری (granularity) بر عملکرد سه مدل در دو معیار ارزیابی مختلف.
Gn نشاندهندهٔ سطح جزئینگری است.
- اثربخشی مسیریابی: عملکرد برتر UniversalRAG نسبت به رویکرد «یکپارچه» (Unified)، اهمیت استراتژی مسیریابی برای غلبه بر «شکاف رسانهای» را برجسته میکند.
- قدرت مسیریابهای آموزشدیده: مدلهای UniversalRAG با مسیریابهای آموزشدیده، در اکثر آزمایشها نتایج بهتری نسبت به مدل با مسیریاب بدون نیاز به آموزش کسب کردهاند. این به دلیل بهینهسازی صریح مسیریاب برای وظیفه مسیریابی در طول آموزش است. با این حال، مسیریاب بدون نیاز به آموزش نیز همچنان عملکرد قابل قبولی داشته و از سایر روشهای پایه بهتر عمل کرده است.
- اهمیت چنددانهبندی: آزمایشها نشان دادهاند که پشتیبانی از سطوح مختلف دانهبندی (هم درشت و هم ریز) در پیکرههای متنی و ویدیویی، به بهبود عملکرد UniversalRAG کمک میکند. این امکان را به مدل میدهد تا مقدار اطلاعات مناسب و متناسب با هر سوال را بازیابی کند. تصویر۵ این بهبود عملکرد را هنگام استفاده از دانهبندی نشان میدهد.
- عملکرد بر روی دادههای خارج از دامنه: برای ارزیابی قابلیت تعمیمپذیری، UniversalRAG بر روی مجموعه دادههایی که مسیریاب آموزشدیده قبلاً ندیده بود، آزمایش شد. در این سناریو، مسیریاب GPT-4o (بدون نیاز به آموزش) دقت مسیریابی بالاتری از خود نشان داد. برای بهرهگیری از نقاط قوت هر دو رویکرد، یک «مسیریاب ترکیبی» (Ensemble Router) پیشنهاد شده که از مسیریاب آموزشدیده برای سوالات مشابه دادههای آموزشی و از مسیریاب بدون نیاز به آموزش برای سوالات ناآشنا استفاده میکند. نتایج مربوط به این بخش در جدول زیر قابل مشاهده است.

تصویر۶: دقت Router و عملکرد تولید محتوا در روشهای مختلف بازیابی، بر روی دادههای دروندامنهای و بیروندامنهای.
مثالهای کاربردی از قدرت UniversalRAG
برای درک بهتر نحوه عملکرد UniversalRAG، به چند مثال اشاره میکنیم:
اهمیت نوع محتوا (تصویر در مقابل متن):
در جدول زیر، سوال «در مراسم راهاندازی کشتی USNS Carl Brashear در سن دیگو، بادکنکها چه رنگی بودند؟» مطرح میشود.
- یک RAG مبتنی بر متن (TextRAG) اطلاعاتی کلی درباره یک کارگردان به نام رندال دارک بازیابی میکند که هیچ ارتباطی با رنگ بادکنکها ندارد.
- یک RAG مبتنی بر ویدیو (VideoRAG) نیز تصاویری از بادبان و بخشهای دیگر کشتی را نشان میدهد که باز هم بیربط هستند.
- اما UniversalRAG به درستی تشخیص میدهد که این سوال نیاز به اطلاعات بصری دارد، آن را به پیکره «تصویر» مسیریابی کرده و تصویری از کشتی با بادکنکهای قرمز، سفید و آبی بازیابی میکند و پاسخ صحیح را ارائه میدهد.
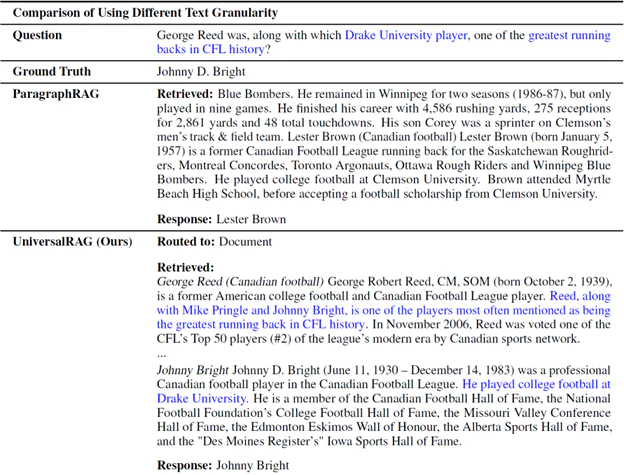
اهمیت دانهبندی متن (سند در مقابل پاراگراف):
در تصویر ۷ سوال پیچیدهتری مطرح میشود: «جرج رید، به همراه کدام بازیکن دانشگاه دریک، یکی از بهترین بازیکنان خط حمله در تاریخ CFL بود؟»
- یک RAG مبتنی بر پاراگراف (ParagraphRAG) پاراگرافی درباره یک بازیکن دیگر به نام لستر براون بازیابی میکند و پاسخ اشتباه میدهد.
- اما UniversalRAG تشخیص میدهد که این سوال به اطلاعات از چندین بخش و احتمالاً چندین موجودیت نیاز دارد، آن را به پیکره «سند» مسیریابی میکند، سندی کاملتر شامل اطلاعات جرج رید و جانی برایت (بازیکن دانشگاه دریک) را بازیابی کرده و پاسخ صحیح «جانی دی. برایت» را ارائه میدهد.

تصویر۷: مطالعه موردی مقایسه RAG در حالت تکمودالیتی با UniversalRAG.
اهمیت دانهبندی ویدیو (کلیپ در مقابل ویدیوی کامل):
در زیر، سوالی درباره مسابقه دوی ۱۰۰ متر مردان در المپیک ۲۰۱۲ لندن مطرح میشود: «در دور اول گروه ۵، با حضور یوسین بولت و یوهان بلیک، چه کسی اول شد؟»
تصویر۶: دقت Router و عملکرد تولید محتوا در روشهای مختلف بازیابی، بر روی دادههای دروندامنهای و بیروندامنهای.
- یک RAG مبتنی بر ویدیوی کامل (VideoRAG)، کل ویدیوی مسابقه (حدود ۳۸ ثانیه) را بازیابی میکند که ممکن است شامل بخشهای غیرضروری زیادی باشد و منجر به پاسخ اشتباه «یوسین بولت» (گزینه B) شود.
- یک UniversalRAG تشخیص میدهد که سوال به یک لحظه خاص در ویدیو اشاره دارد، آن را به پیکره «کلیپ» مسیریابی میکند، یک کلیپ کوتاه و متمرکزتر (حدود ۳ ثانیه از ۲۵:۵۷ تا ۲۹:۲۲) از لحظه پایان مسابقه که آسافا پاول را نشان میدهد، بازیابی کرده و پاسخ صحیح «آسافا پاول» (گزینه C) را ارائه میدهد.
اهمیت UniversalRAG برای آینده هوش مصنوعی
گام مهمی به سوی ساخت سیستمهای هوش مصنوعی تطبیقپذیرتر و قابل اعتمادتر، چارچوب UniversalRAG است. با توانایی درک نیازهای اطلاعاتی متنوع کاربران و بازیابی هوشمندانه از منابع گسترده متنی، تصویری و ویدیویی با سطوح جزئیات مختلف، این چارچوب پتانسیل بالایی برای بهبود قابل توجه برنامههای کاربردی زیر دارد:
- دستیاران مجازی و چتباتها: ارائه پاسخهای دقیقتر، جامعتر و مبتنی بر شواهد محکم.
- موتورهای جستجوی نسل جدید: فراتر رفتن از جستجوی کلیدواژهای ساده و ارائه پاسخهای مستقیم و چندوجهی.
- ابزارهای تحلیل دادههای پیچیده: استخراج بینش از ترکیبی از گزارشهای متنی، نمودارهای تصویری و ارائههای ویدیویی.
- سیستمهای آموزشی شخصیسازیشده: ارائه محتوای آموزشی متناسب با نیاز و سبک یادگیری هر فرد، با استفاده از بهترین ترکیب از متن، تصویر و ویدیو.
جمعبندی
چارچوب UniversalRAG با ارائه یک راه حل نوآورانه برای مسیریابی آگاه از نوع محتوا و دانهبندی، محدودیتهای سیستمهای RAG فعلی را به چالش میکشد. این رویکرد به مدلهای زبانی بزرگ اجازه میدهد تا از طیف وسیعتری از دانش جهانی بهرهمند شوند و پاسخهایی تولید کنند که نه تنها دقیقتر، بلکه مرتبطتر و مفیدتر برای کاربران هستند. UniversalRAG مسیری را برای توسعه سیستمهای هوش مصنوعی باز میکند که قادر به درک و تعامل با دنیای پیچیده و چندوجهی اطلاعات، به شیوهای هوشمندانهتر هستند.
